
基于深度卷积生成对抗网络和近红外高光谱成像技术对不健康小麦籽粒识别
背景:
实际生产过程中,经常发现健康小麦籽粒中混杂着损坏的、发芽的、霉变的和感染萎蔫病的籽粒。受损的麦粒失去了生存能力,发芽和霉变的麦粒没有育种价值。因此,区分健康与不健康麦粒对于育种具有重要意义。近年来,将高光谱成像技术与机器学习、深度学习相结合的方法在种子识别领域得到了广泛的应用。但在实际应用中,处于不健康状态的麦粒数量有限,导致数据量少或数据分布不平衡。此外,数据量较小的类别很容易被数据量较大的类别所忽略。因此,基于数据驱动的机器学习或深度学习算法的准确率较低。
这些问题应该从根本上通过增加训练数据来解决,即从原始数据中产生更多的数据。生成对抗网络(Generative adversarial network, GAN)是一种深度学习模型,可用于学习原始数据的复杂分布。采用深度卷积神经网络(Deep convolutional neural networks, DCNN)结合GAN增强高光谱训练样本并建立模型。DCNN分类器与GAN结合使用的准确率为95.32%,未结合的准确率为92.94%。由此可见其方法的优越性。然而,在种子识别领域,GAN几乎从未被用于生成数据以提高分类器的性能。为此,本文提出了一种基于深度卷积对抗生成网络(Deep convolutional generative adversarial networks, DCGAN)的数据增强方法。然后采用决策树(DT)、支持向量机(SVM)和卷积神经网络(CNN)相结合的高光谱成像技术对小麦健康和不健康籽粒进行识别。
本文的主要目标是:(1)评估基于DCGAN的生成样本的质量;(2)比较扩展不平衡数据集前后不同分类算法的性能;(3)在上一步的基础上,通过DCGAN增加训练样本,评估不同分类算法的准确率是否可以进一步提高;(4)评价训练样本数量的变化对各分类器分类性能的影响。
试验设计
中国农业大学吉海彦教授团队利用GaiaSorter推扫式高光谱成像系统(江苏双利合谱公司)(图1)获取了健康、发芽、霉变和萎蔫小麦籽粒的高光谱影像。光谱范围为866.4 - 1701.0 nm。四种籽粒分别获取了100、82、91和74个样本。

图1 高光谱系统结构
GAN是由生成器(Generator)和判别器(Discriminator)两个部分组成(图2)。生成器接收随机噪声,通过生成模型生成假样本。判别器的输入是一个样本,判别网络判断输入样本是来自于真实样本还是生成器生成的假样本。通过不断训练,生成器*终生成尽可能真实的数据。本研究采用DCGAN作为增强数据的方法。DCGAN主要的改进是在网络结构上,生成器和判别器中均使用了一个卷积神经网络,同时改进了卷积神经网络部分结构(图3)。
GAN生成的光谱数据的质量评估主要分为两个方面,一是生成的光谱与真实光谱的相似度,二是生成的光谱的多样性。光谱的相似度主要从三个方面进行评价。一方面,计算生成的光谱数据与真实光谱数据之间的均方根误差(RMSE),其次,通过对不同时期生成的光谱进行可视化,观察其与真实光谱的差异,*后,利用主成分分析(PCA)对生成数据与真实数据进行降维,观察其主成分分布范围,判断生成数据与真实数据的相似度。
本研究使用的三种分类算法为决策树(DT)、支持向量机(SVM)和卷积神经网络(CNN)。试验分为两个阶段,**阶段,将不平衡的小麦籽粒数据集扩展到平衡状态后,记录变化前后测试集的准确率,判断基于DCGAN的数据增强方法是否有效。**阶段是在**阶段试验的基础上,将生成的光谱数据加入到平衡的小麦籽粒数据集中,增加训练集的数量,从而判断数据增强对模型性能的影响。
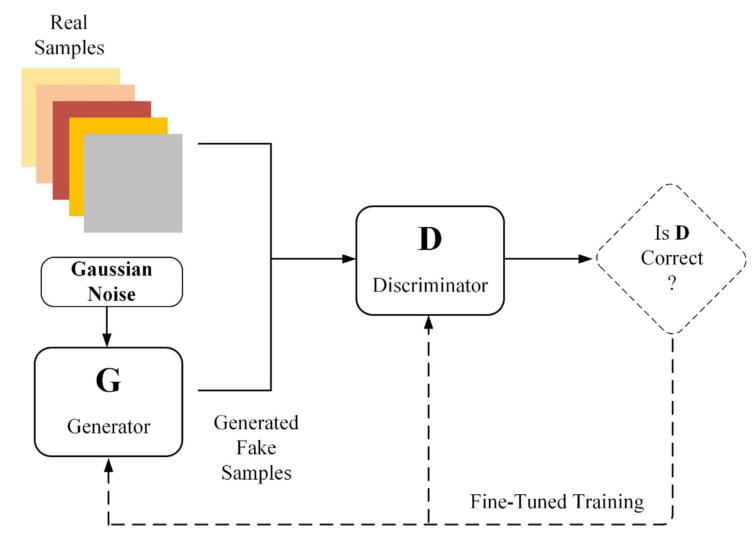
图2 GAN结构
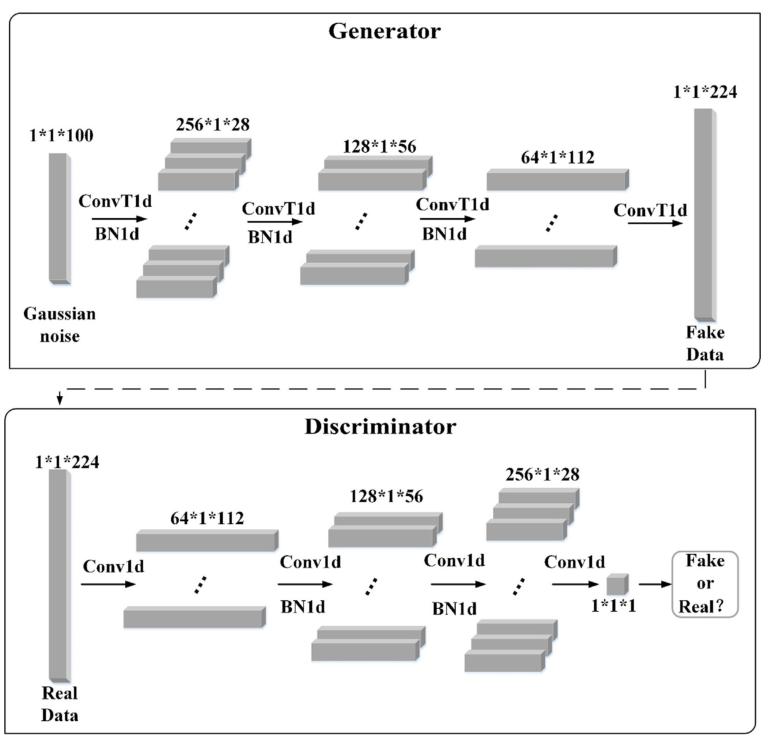
图3 DCGAN结构
结论
从图4可以看出,4种小麦籽粒的光谱特征相似,萎蔫籽粒的平均光谱反射率显著高于其他3种,健康籽粒的光谱反射率值差异*大。霉变小麦籽粒受到**侵染的影响,籽粒表面颜色和形状发生变化,但对含水率影响不大。因此,与萎蔫小麦籽粒相比,其光谱反射率值接近健康籽粒。萌发籽粒与健康籽粒不同,因为其萌发需要消耗能量。但与其他两种籽粒相比,其光谱反射率值*接近健康小麦籽粒。在1150 ~ 1300 nm和1400 ~ 1650 nm两处波段的差异为后续分类算法的建立提供了基础。
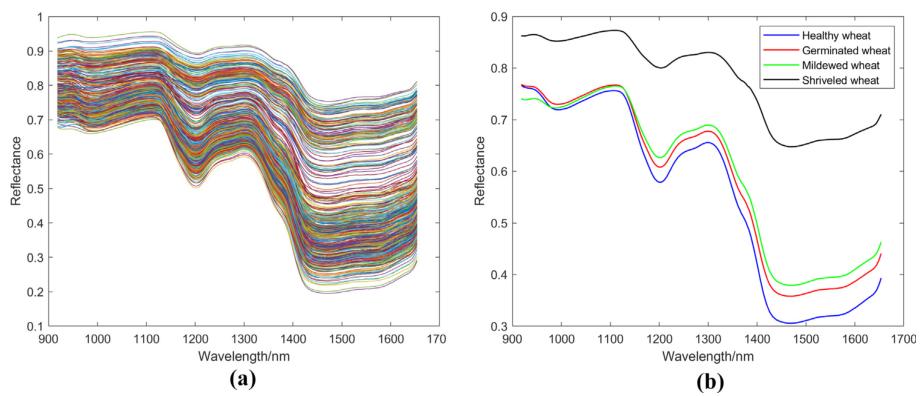
图4 籽粒光谱。所有小麦籽粒的光谱(a);小麦籽粒在四种不同状态下的平均光谱(b)。
对生成的光谱数据与真实光谱的相似度进行评估。由表1可以看出,epoch从0增加到50时,生成数据与真实数据的RMSE呈断崖式下降。虽然epoch为50时,RMSE已经较小(0.064324),但是从5c和5h中可以看出生成的光谱大致轮廓与真实光谱相似,但存在较大噪声。1000、1500、2000次epoch下的生成光谱曲线越来越接近真实光谱,噪声逐渐降低,直到2000次epoch下生成的光谱噪声基本消失。从图6可以看出,无论迭代多少次,生成光谱的PC1和PC2均包含在真实光谱中,并且无法将两者区分开来。这也说明了DCGAN生成的光谱与实际光谱的相似性。随着epoch次数的增加,PC1和PC2的分布范围逐渐变宽,直到在2000个epoch时达到*大。部分生成的光谱主成分的分布范围超过了真实光谱。*后,综合考虑多种评价指标,选取经过2000次epoch后训练生成的光谱作为后续实验所需的样本。
表1 不同epoch下小麦籽粒实测数据与生成数据的均方根误差

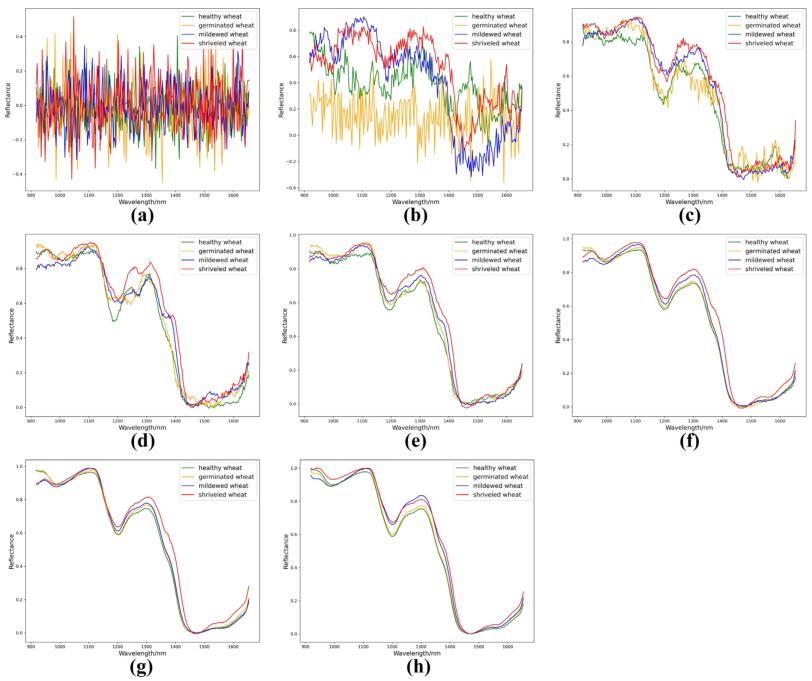
图5 不同epoch下的生成光谱数据和真实光谱数据的可视化
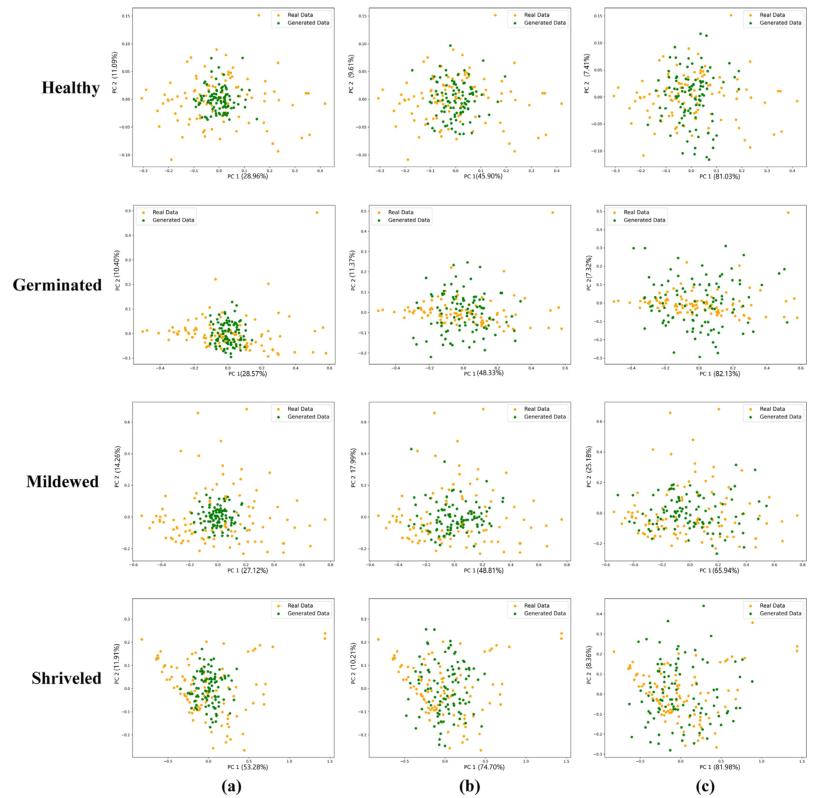
图6 500、1500、2000次epoch下生成的光谱数据的主成分降维图
表4给出了分类器在原始数据集和平衡数据集上的对比实验结果。数据平衡后,所有分类器的测试集的准确率都得到了提高。其中,准确率提高幅度*小的分类器是CNN模型,准确率提高了8.34%。提升*大的是DT模型。准确率从51.67%提高到80.83%,这也表明分类器受样本是否平衡的影响明显。从图7可以看出,数据扩展后,每个类别的误分类次数都在减少。虽然这三种分类器从增加的数据样本中学习到了更多的特征,准确率也有了很大的提高,但*终测试集的准确率仍然不能令人满意。此外,CNN模型还存在过拟合的风险,其训练集准确率与测试集准确率相差超过3%。这可能是由于训练样本较少,CNN模型无法学习到更深层的特征,导致过拟合。因此,需要更多的样本来提高分类器的识别能力。
表2 不同分类器对原始数据集和平衡数据集的分类精度

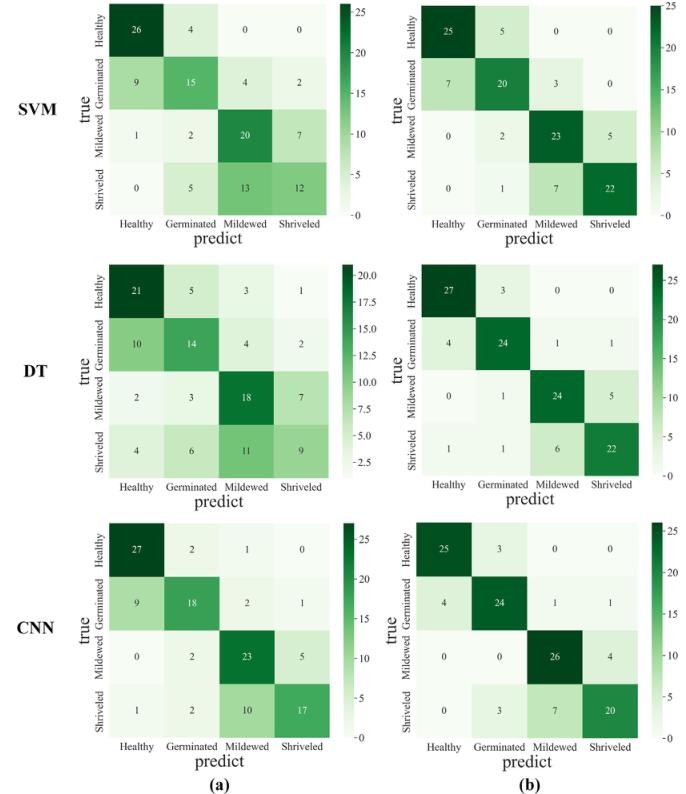
图7 三种分类器在不平衡数据集(a)和平衡数据集(b)上分类结果的混淆矩阵
从表3和图8可以看出,随着加入训练集样本数量的不断增加,SVM、DT、CNN模型的性能变化是不同的。在每种小麦籽粒的训练集数据中加入50个样本,SVM模型的测试集准确率从75%提高到80%。然后,当训练样本数量增加200个时,SVM模型的分类准确率*高,达到85.83%。随着样品的不断加入,其准确度在80% - 85%之间波动。这表明SVM仍然从这些增量样本中学习到一些特征,但学习到的特征相对有限。DT模型的准确率虽然也有所提高,但提高幅度较小,其准确率一直在80%到85%之间波动。这表明DT模型从生成样本中获得的收益很小。对于CNN模型,随着样本数量的增加,其准确率从79.17%提高到96.67%,总计提高了17.50%。之后,它的测试集准确率开始在95%左右振荡,并没有随着训练样本的增加而增加。这可能是由于DCGAN在生成样本时,作为其近似目标的真实样本数量相对较少。因此,虽然选择了相似性和多样性*好的生成样本,但与现实世界中的真实样本相比,其多样性仍然比较一般。然而,与SVM和DT两种机器学习模型相比,CNN具有更强的数据拟合能力和分类能力。随着样本数量的增加,它可以学习到更多的特征。
结合以上两阶段的实验结果表明,基于DCGAN的数据增强模型能够为不平衡数据集生成可靠的数据样本,从而帮助分类任务。此外,在DCGAN的帮助下,SVM、DT和CNN模型的识别能力都得到了提升,其中CNN的提升效果*为显著。这也表明基于DCGAN的数据增强模型对于样本较少的数据集具有扩展样本的能力。以上研究为数据集不平衡或数据集有限条件下的高精度分类提供技术支撑。
表3 不同分类器在加入不同样本数的测试集上的准确率

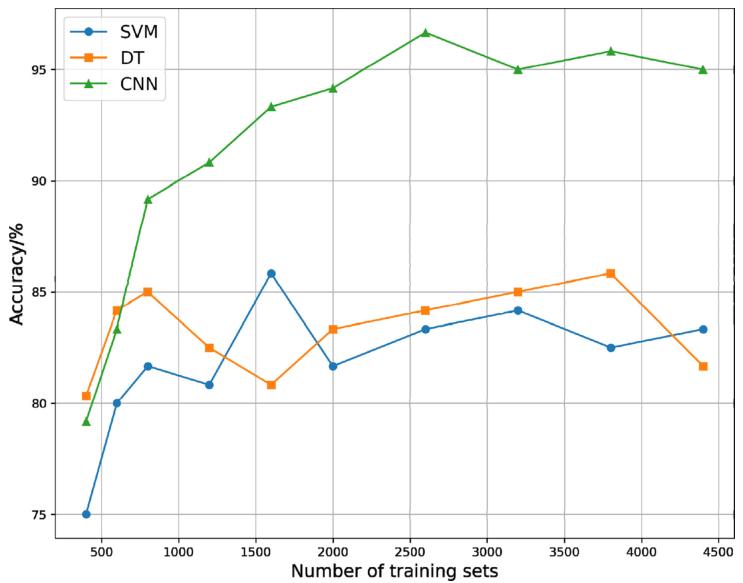
图8 不同分类器的分类精度随训练集数据的增加而变化
作者信息
吉海彦,博士,中国农业大学信息与电气工程学院教授,博士生导师。
主要研究方向:高光谱成像技术及其农业应用研究、近红外光谱分析技术及其应用研究、农业生物信息检测与处理。
参考文献
Li, H., Zhang, L., Sun, H., Rao, Z.H., & Ji, H.Y. (2022). Discrimination of unsound wheat kernels based on deep convolutional generative adversarial network and near-infrared hyperspectral imaging technology. Spectrochimica Acta Part A: Molecular and Biomolecular Spectroscopy, 268, 120722.
https://doi.org/10.1016/j.saa.2021.120722
