
高光谱成像和化学计量学无损监测水稻水分和脂肪酸含量
背景
水分含量(Moisture content, MC)和脂肪酸含量(Fatty acid content, FAC)是大米品质的重要指标,影响大米的存储和食用品质。因此,建立一种快速、准确、无损的MC和FAC检测方法至关重要。
可见/近红外光谱可以响应样品中的某些含氢基团,从而获得样品中的内部化学信息。该技术已被用于检测农产品中的水分和脂肪酸含量。同时,与可见光/近红外光谱相比,高光谱成像(Hyperspectral imaging, HSI)技术具有光谱与图像相结合的优势。利用每个像素点的光谱预测水稻的MC和FAC,形成水稻的MC和FAC的可视化分布,使检测结果更加直观。但是,HSI技术也存在数据量大、实时性差等缺点,难以在实际中应用。然而,这些问题可以通过数据降维和特征波长选择来解决。
本研究的目的是结合HSI技术与化学计量学方法,建立一种快速简便的水稻MC和FAC检测方法。(1)采用不同的预处理方法对大米和精米的光谱进行预处理,建立了MC和FAC的全波段预测模型。*后根据模型性能确定*佳预处理方法。(2)采用两种变量选择方法筛选大米和精米在900~1700 nm区域的MC和FAC的显著波长。(3)比较了MC和FAC模型在大米和精米中的性能,并分析了稻壳对MC和FAC模型性能的影响。(4)利用*佳模型预测每个像素点的MC和FAC,实现水稻样品MC和FAC的可视化。
试验设计
浙江农林大学孙通副教授团队利用GaiaField-N17E高光谱成像系统(江苏双利合谱)获取了13个水稻品种的大米和精米高光谱影像(图1)。近红外高光谱成像仪的光谱范围为900~1700 nm,空间分辨率为640像素,波段数为512,光谱分辨率为5 nm。对获得的高光谱影像利用OTSU方法获取其前景像素,并计算大米和精米平均光谱。
预处理可以去除高频随机噪声和基线漂移等噪声,提高模型性能。本研究采用了5种预处理方法,包括多元散射校正(MSC)、标准正态变量变换(SNV)、Savitzky-Golay(SG)平滑、SG+一阶导数和SG导数。根据全波段模型的性能,选择*合适的预处理方法。为提高计算速度,减少数据冗余,本研究采用竞争自适应重加权采样(CARS)和连续投影算法(SPA)选择大米/精米中MC和FAC的显著波长。
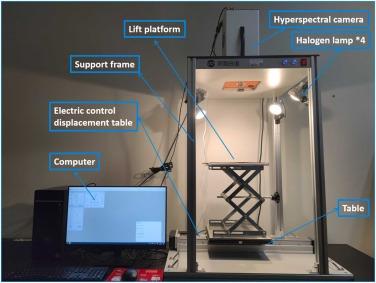
图1高光谱成像系统
结论
大米和精米在900~1700 nm波长范围内的原始反射光谱如图2所示。从图2可以看出,大米和精米的光谱在900~1400 nm波长范围内具有相同的趋势。然而,大米的反射光谱逐渐增加,而精米的反射光谱在1400~1700 nm波长范围内趋于稳定。此外,大米光谱的反射率值普遍高于精米。这可能是由于大米和精米的颜色、光滑度和透明度不同造成的。在960、1200和1450 nm处有三个明显的峰。960 nm左右的峰值可能是由水和碳水化合物中O-H二阶泛音的协同作用引起的。1200 nm左右的峰值与样品的MC有关,1450 nm左右的峰值归因于O-H拉伸**泛音。
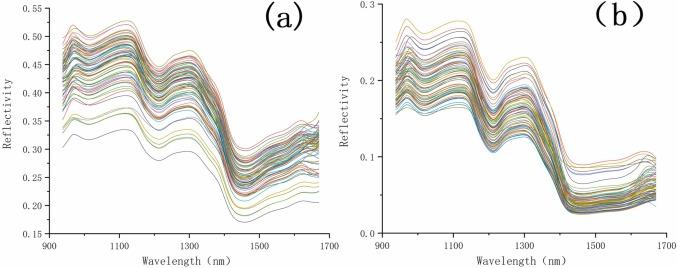
图2 大米(a)和精米(b)样品的原始光谱
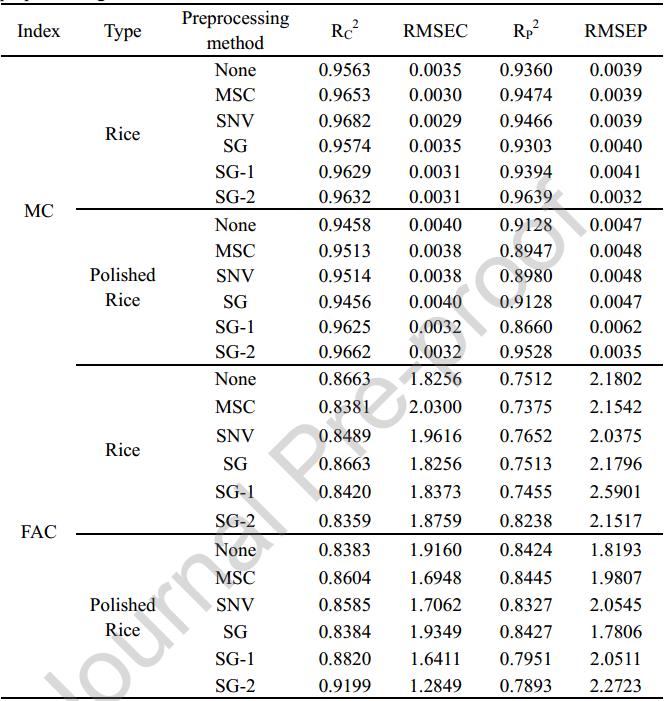
采用5种预处理方法对大米和精米样品的光谱进行处理,利用PLSR算法建立MC和FAC的估测模型。由表1可知,在“大米-水分”模型中,SNV和SG-2预处理效果更好。采用SNV预处理建立的模型R2较高,达到0.9682。但该模型不稳定,鲁棒性较差。因此,SG-2模型的性能优于SNV模型。在“大米-脂肪酸”模型中,SG-2是*佳的预处理方法。对于“精米-水分”模型,SG-2预处理的R2较高。综上所述,在“大米-水分”、“精米-水分”和“大米-脂肪酸”3种预测模型中,SG-2是*佳的预处理方法。而在“精米-脂肪酸”模型中,SG平滑是*好的预处理方法,模型的R2p和RMSEP分别为0.8427和1.7806。
从表1可以看出,大米中MC的模型性能优于精米。这是因为稻壳含有水分,其吸水能力高于精米。因此,当大米样品经过水处理后,稻壳比精米吸收更多的水分。因此,大米光谱中含有的水分信息比精米光谱中含有的水分信息更多。相比之下,精米中FAC的模型性能优于大米。稻壳主要由纤维素、半纤维素、木质素等成分组成,其中不含脂肪酸。稻壳中存在的干扰信息会影响建模过程中脂肪酸的预测。因此,得到的光谱信息可能会受到谷壳的干扰,导致精米的预测精度降低。
表1 不同预处理方法下样品中水分和脂肪酸的PLS模型预测结果
由于采用SG或SG-2预处理的MC和FAC模型效果*好,因此对这些光谱进行了CARS和SPA特征优选。由表2可以看出,相较于CARS,SPA选择更少的重要波长,使实际应用更容易,同时SPA模型的RPD值较高,模型精度较高。此外,SPA模型的性能优于全波段模型,这表明SPA选择的波长几乎包含了MC或FAC的所有有效信息。与全波段模型的结果相似,SPA模型对大米中MC的预测精度高于精米,而对大米中FAC的预测精度低于精米。“大米-水分”、“精米-水分”、“大米-脂肪酸”的*佳模型为“SG2-SPA-PLS”,“精米-脂肪酸”的*佳模型为“SG-SPA-PLS”。
SPA选择的波长如表3所示。MC模型选择的964.17、965.74、975.16、978.29、1373.75和1395.72 nm波长与水分波长相似,归功于O-H拉伸的**、**和第三泛音。对于FAC模型,选择的1095.99、1387.87和1516.56 nm波长归功于C-H的一、二泛音和-CH2基团的拉伸,选取的939.06、964.17和967.31 nm波长主要来自于O-H键的弯曲振动。
表2 使用选定波长的样品中水分和脂肪酸的PLS模型预测结果

表3 由SPA选择的波长

通过Fearn(1996)提出的方法验证稻壳对MC和FAC预测精度的影响。在95%置信水平下计算区间是否包含0。如果它包含0,则偏差在5%的水平上没有显著差异。由表4可知,大米和精米中MC的预测误差计算区间均为0,而FAC的不为0。这表明大米与精米中FAC的预测误差存在显著差异,因此稻壳对FAC的预测精度有一定的影响。
表4 大米和精米的水分和脂肪酸含量在95%置信水平上存在显著差异
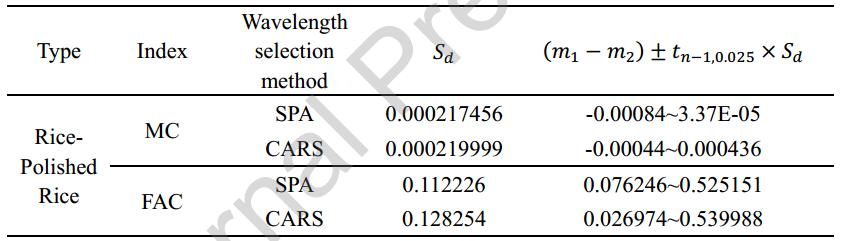
图3为不同水分梯度下水稻样品MC的可视化结果。可以看出,水稻样本的MC越高,可视化图像中的红色域越大,而水稻样本的MC越低,可视化图像中的蓝色*域越大。这与大米样本的实际MC一致,说明MC模型对每个像素的MC预测是准确的。此外,可视化图像中大米样品的MC分布不均匀,这可能是由于样品处理过程中吸湿不均匀造成的。图4为大米样品FAC可视化结果。FAC模型可以准确预测每个像素的FAC。可视化可以直观地反映水稻中MC和FAC的空间变化,可以在像元水平上了解MC和FAC的分布情况。因此,在储存前检验和储存监测中,可以在很小的范围内检测到异常的MC和FAC,从而保证了大米的质量**。
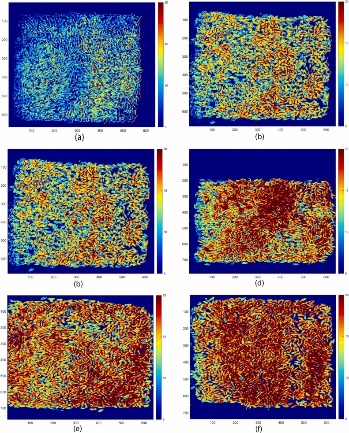
图3 大米含水量可视化图
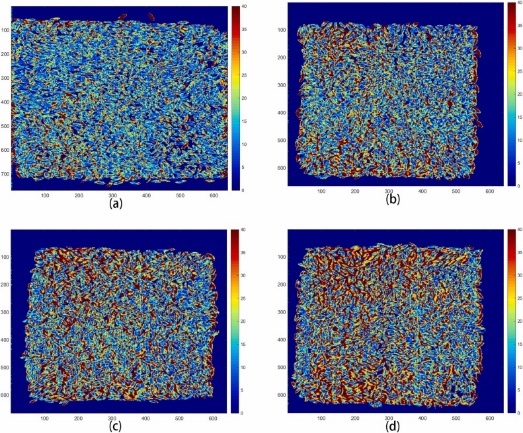
图4 大米脂肪酸含量可视化图
作者信息
孙通,博士,浙江农林大学光机电工程学院副教授,硕士生导师。
主要研究方向:农林产品光谱智能检测技术研究及装备开发。
参考文献:
Song, Y., Cao, S., Chu, X., Zhou, Y., Xu, Y., Sun, T., Zhou, G., & Liu, X. (2023). Non-Destructive Detection of Moisture and Fatty Acid Content in Rice using Hyperspectral Imaging and Chemometrics. Journal of Food Composition and Analysis, 11.
https://doi.org/10.1016/j.jfca.2023.105397
